







Keeping track of your finances can feel overwhelming, whether...
The modern skincare routine is evolving, moving away from...

In today’s competitive business environment the importance of...

In terms of heating and cooling your house, opting...
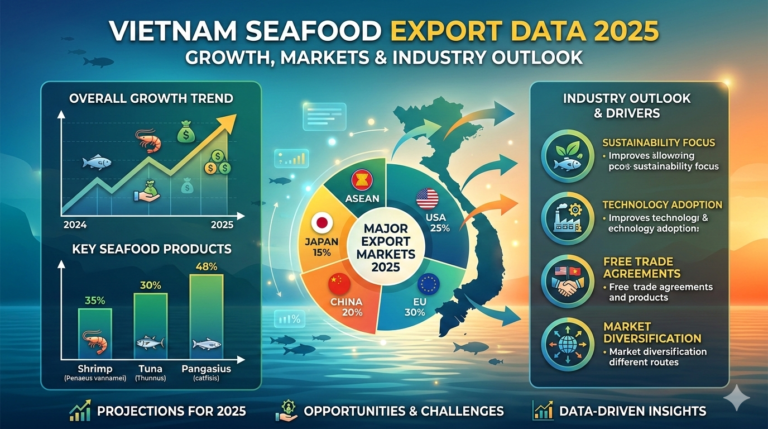
Vietnam has firmly positioned itself as a powerhouse in...

If you are a certified EMT looking for better...

In today’s competitive marketplace, your storefront is more than...